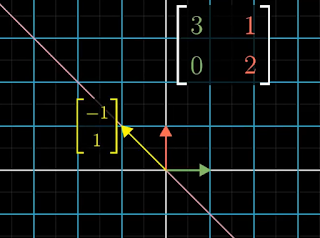
 |
| Figure 1: Before transformation |
This is Part 8 in a
series on linear algebra [1].
A vector that remains on its
span [2] when a linear transformation is applied to it is termed an
eigenvector of that transformation. The amount that it is scaled is called an eigenvalue.
For example,
Figure 1 shows a yellow arrow that will be transformed by the indicated matrix. The purple line is the span of the yellow arrow.
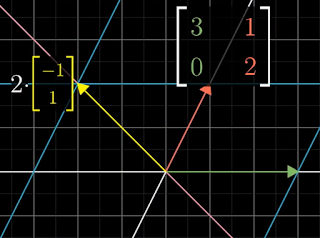 |
| Figure 2: After transformation |
Figure 2 shows the yellow arrow after the transformation. Note that the yellow arrow has remained on its span, so it is an eigenvector of the transformation. It has been scaled by a factor of 2, so 2 is the eigenvalue. The eigenvalue is shown as the coefficient of the original vector.
Notice that
i-hat is also an eigenvector and its eigenvalue is 3 (i.e., it is scaled by 3). However
j-hat has not remained on its span, so it is not an eigenvector of the transformation.
Any vector that lies on the span of either the yellow arrow or the green arrow is an eigenvector and it will also have the eigenvalues 2 and 3 respectively. Any vector, such as the red arrow, that does not lie on either of those spans will be rotated off the line that it spans.
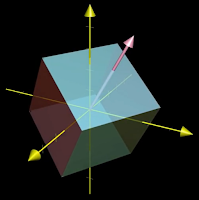 |
| Figure 3: 3D rotation around an axis |
Eigenvalues can be negative which means that after the transformation the arrow will point in the opposite direction along its span.
For one example of where finding an eigenvector is useful, consider a 3D dimensional rotation as in
Figure 3. If you can find an eigenvector for that transformation, a vector that remains on its own span, then you have found the axis of rotation. For rotations the eigenvalue is always 1 since the length of the vector remains the same.
Note that the columns of a matrix describe the landing spots for the basis vectors. However, as illustrated by the 3D rotation, finding the eigenvectors and eigenvalues describes what the transformation does independent of the particular basis vectors used.
An eigenvector equation can be represented as:
Av = λv
where
A is the matrix representing a transformation,
v is the eigenvector and
λ (lambda) is the corresponding eigenvalue (a number). This expression says that the matrix-vector product (
A times
v) gives the same result as just scaling the eigenvector
v by some value
λ. So finding the eigenvectors and their eigenvalues of a matrix
A comes down to finding the values of
v and
λ that make this expression true.
The first step is to convert the right-hand-side of the equation so that it represents a matrix-vector product like the left-hand-side of the equation. This is done by multiplying
λ by the identity matrix
I, as follows:
Av = (λI)v
Now subtracting the right-hand-side and factoring out
v:
Av - λIv = 0
(A - λI)v = 0
We're now looking for a non-zero vector
v such that this new matrix times
v gives the zero vector. The only way it is possible for the product of a matrix with a non-zero vector to become zero is if the transformation associated with that matrix reduces space to a lower dimension, say, from a plane to a line. In that case, the matrix has a determinant of zero. That is:
det(A - λI) = 0
For example, consider the matrix from
Figures 1 and
2:
[3 1]
[0 2]
Now think about subtracting a variable amount λ from each diagonal entry:
[3 1] - λ[1 0] = [3-λ 1]
[0 2] [0 1] [ 0 2-λ]
The goal is to find any values of
λ that will make the determinant of the matrix zero. That is:
det([3-λ 1]) = ad - bc = (3-λ)(2-λ) - 1*0 = (3-λ)(2-λ) = 0
[ 0 2-λ]
Solving this equation, the only possible eigenvalues are
λ = 2 and
λ = 3.
So when
λ equals 2 or 3, the matrix
(A - λI) transforms space onto a line. That means there are non-zero vectors
v such that
(A - λI) times
v equals the zero vector. Recall the reason we care about that is because it means
Av = λv. That is, the vector
v is an eigenvector of
A.
To figure out the eigenvectors that have one of these eigenvalues, plug that value of
λ into the matrix and then solve for which vectors this diagonally-altered matrix sends to zero. Solving with
λ = 2:
[3-2 1][x] = [1 1][x] = x[1] + y[1] = [x+y] = [0]
[ 0 2-2][y] [0 0][y] [0] [0] [ 0] [0]
Since the determinant is zero, there is no unique solution. The solutions are all the vectors on the line described by
y = -x which is the diagonal line spanned by
[-1;1] or the yellow arrow in
Figure 1. Similarly, solving with
λ = 3:
[3-3 1][x] = [0 1][x] = x[0] + y[ 1] = [ y] = [0]
[ 0 2-3][y] [0 -1][y] [0] [-1] [-y] [0]
In this case, the solutions are all the vectors on the line described by
y = 0 which is the horizontal line spanned by
[1;0] or
i-hat in
Figure 1.
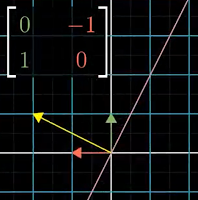 |
| Figure 4: 90° rotation |
Not all transformations have eigenvectors. One example is a 2D 90° counterclockwise rotation which rotates all vectors off their spans as shown in
Figure 4. Consider computing the eigenvalues of this rotation. Subtract
λ from the diagonal elements and look for when the determinant is zero.
det([-λ -1]) = (-λ)(-λ) - -1*1 = 0
[ 1 -λ]
= λ2 + 1 = 0
∴ λ = i or λ = -i
The only roots of that polynomial are the imaginary numbers
i and
-i. Assuming we are only looking for real number solutions, there are no eigenvectors for that transformation. However note that eigenvalues that are complex numbers generally correspond to some kind of rotation in the transformation.
Whenever a matrix has zeroes everywhere other than the diagonal, it is called a
diagonal matrix. The way to interpret this is that all the basis vectors are eigenvectors with the diagonal entries of the matrix being their eigenvalues. That is, a diagonal matrix simply scales the basis vectors. A diagonal matrix can be represented as a vector times the identity matrix
I. For example:
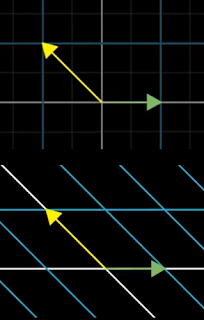 |
| Figure 5: Change of basis |
[-1 0] = [1 0][-1]
[ 0 2] [0 1][ 2]
Therefore, whenever we want to apply a matrix multiplication to a diagonal matrix, it is the same as applying a matrix-vector multiplication, converting an O(N
2) operation into O(N).
If a transformation has enough eigenvectors such that you can choose a set that spans the full space, then you can change your coordinate system so that these eigenvectors are your basis vectors. For example, using the eigenvectors for the matrix from
Figure 1 as the change of basis matrix (the green and yellow arrows):
[1 -1]-1[3 1][1 -1] = [3 0]
[0 1] [0 2][0 1] [0 2]
This new matrix is guaranteed to be diagonal with its corresponding eigenvalues down that diagonal. The new basis is called an eigenbasis with
Figure 5 showing the change of basis. Applying the transformation will scale the new basis vectors by those eigenvalues, that is, the green arrow by 3 and the yellow arrow by 2.
Next up:
vector spaces
--
[2] A vector that remains on its span either points in the same direction or points in the opposite direction (the negative direction).





















